

Fine-tuning itu seperti proses menyesuaikan model AI umum supaya lebih cocok dan maksimal untuk tugas tertentu. Khususnya dalam model generatif seperti text-to-image, fine-tuning dengan dataset yang pas bisa bikin hasilnya lebih sesuai dengan harapan pengguna.
Hal ini memungkinkan proses pembuatan visual yang lebih cepat, lebih konsisten, dan sesuai harapan. Tapi, apa Itu dataset yang “tepat”?
Berbeda dengan dataset pretraining yang mengutamakan skala, dataset untuk refinement mengutamakan kualitas. Dan bukan sembarang kualitas, tapi relevansi yaitu kumpulan gambar yang mencerminkan gaya, komposisi, dan makna visual yang benar-benar penting bagi pengguna akhir.
Selama ini, memilih data yang relevan lebih sering dianggap sebagai seni daripada sains. Kami ingin mengubah hal itu.
Dari Proxy Metrics ke Skor Berbasis Perilaku
Banyak tim sebelumnya mengandalkan proxy metrics spekulatif seperti aesthetic score dari LAION untuk memperkirakan kualitas gambar. Namun, metrik ini hanya mencerminkan penilaian estetika subjektif yang belum tentu mewakili kepuasan pengguna.

Di Shutterstock, kami mengambil pendekatan berbeda: menentukan dataset berdasarkan perilaku nyata pengguna.
Awalnya, Shutterstock menggunakan gambar-gambar paling laris di pasar stok kami untuk fine-tuning. Tapi ternyata ada celah besar: gambar yang laris di pasar stok belum tentu menghasilkan keluaran yang memuaskan bagi pengguna model generatif. Tujuan dan preferensi visual mereka berbeda-beda.
Memahami Generative Aesthetic Score
Di sinilah posisi unik Shutterstock memainkan peran penting. Dengan lebih dari 100 juta gambar AI yang telah dilisensikan, kami memiliki data perilaku nyata untuk melatih model pembelajaran mesin yang dapat memprediksi apa yang benar-benar disukai pengguna generatif.
Model ini menghasilkan Generative Aesthetic Score, sinyal prediktif yang sangat berkorelasi dengan keterlibatan pengguna.
Beberapa hasilnya:
Gambar AI dengan engagement tinggi memiliki skor 8,3% lebih tinggi dibanding gambar yang tidak menarik (bandingkan dengan 1,4% pada LAION).
Skor ini mampu meranking performa model generatif dengan korelasi 0,86 terhadap keterlibatan nyata pengguna (dibanding 0,39 dari LAION).
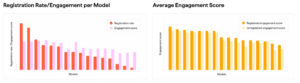
Generative Aesthetic Score juga berguna untuk pemilihan checkpoint selama eksperimen fine-tuning dan tetap akurat seiring perubahan selera pengguna.
Kualitas & Variasi: Kunci Dataset yang Optimal
Kualitas saja tidak cukup, variasi visual juga penting. Untuk itu, kami menggunakan strategi clustering-based sampling:
Gambar diklaster berdasarkan kesamaan visual.
Dari setiap klaster, kami memilih gambar dengan skor tertinggi berdasarkan Generative Aesthetic Score.
Jumlah klaster disesuaikan agar seimbang antara kesesuaian konten dan variasi visual yang menarik.
Hasil akhirnya: dataset refinement yang tidak hanya sesuai dengan preferensi pengguna, tetapi juga kaya variasi visual dan minim redundansi.
Hasil Eksperimen: Kesesuaian Prompt & Engagement
Kami membandingkan hasil fine-tuning model dasar dengan:
Dataset baseline (gambar stok populer)
Dataset optimal (berdasarkan skor generatif dan clustering)

Hasilnya:
+1,1 poin CLIP score (kesesuaian dengan prompt)
+17% skor Generative Aesthetic
Secara visual, model yang di-fine-tune dengan dataset optimal menghasilkan gambar yang lebih tajam, relevan, dan memenuhi ekspektasi pengguna.
Peran Penting Caption: Bahasa adalah Kunci
Visual memang penting, tapi bahasa (tepatnya caption) sama pentingnya. Caption berkualitas tinggi membantu model belajar memetakan bahasa ke visual dengan lebih akurat.
Kami menemukan bahwa:
Caption dari kontributor Shutterstock lebih baik dari hasil scraping biasa.
Tapi caption sintetik dari Vision-Language Models (VLMs) bahkan lebih unggul.
Dengan 80% caption sintetik, model fine-tuning kami menunjukkan:
+0,5 CLIP score
+1,6% Generative Aesthetic Score
Caption ini memungkinkan model belajar visualisasi nuansa bahasa yang lebih kompleks dan relevan secara emosional.
Data Adalah Tuas, Fine-Tuning Adalah Titik Tumpunya
Jika kamu sedang membangun atau mengevaluasi pipeline model generatif, pelajaran pentingnya adalah:
Kualitas data mengalahkan kuantitas data. Dan kualitas terbaik adalah yang selaras dengan pengguna kamu.
Di Shutterstock, kami telah membangun pipeline yang:
Memilih dan memberi skor gambar berdasarkan perilaku pengguna
Mengelompokkan konten untuk menjaga variasi
Menghasilkan caption sintetik yang kaya dan kontekstual
Jika kamu tertarik membangun pipeline internal serupa, atau ingin melisensikan dataset generatif berkualitas tinggi yang siap digunakan, tim kami siap membantu.
Artikel asli ditulis oleh Raúl Gómez Bruballa : How Dataset Quality and Caption Richness Shape Fine-Tuned Text-to-Image Models